


Big Data hat in den letzten Jahren immer mehr an Bedeutung gewonnen. Unternehmen sammeln immer mehr Daten, die sie für ihre Geschäftsprozesse und Entscheidungen nutzen möchten. Eine Big-Data-Plattform ermöglicht es Unternehmen, diese Daten zu sammeln, zu speichern und zu analysieren.
Eine Big-Data-Plattform besteht aus verschiedenen Komponenten, die zusammenarbeiten, um die Datenaufnahme, -verarbeitung und –analyse zu ermöglichen. Zu diesen Komponenten gehören unter anderem Data Warehousing, Echtzeit-Dateneingabe, maschinelles Lernen (ML) und künstliche Intelligenz (KI). Unternehmen nutzen häufig Data Lakes, um Daten aus verschiedenen Quellen im Unternehmen zusammenzuführen und diese besser zu verwalten und allen Abteilungen zugänglich zu machen.
Durch den Aufbau einer Data Lakehouse-Architektur auf AWS können Unternehmen Daten in einem Data Lake speichern und gleichzeitig spezielle Tools eines klassischen Data Warehouse nutzen, um Entscheidungen schnell und flexibel zu treffen. Diese Art von Architektur bietet Unternehmen ein unschlagbares Preis-Leistungs-Verhältnis.
Amazon Managed Workflows for Apache Airflow (AWS MWAA) ermöglicht es Unternehmen, die Bewegung und Transformation von Daten in einer Lakehouse-Architektur auf AWS durchzuführen. Um dies zu veranschaulichen wird ein Beispiel mit dem öffentlich verfügbaren GDELT-Datensatz (Global Dataset of Events, Location, and Tone) gezeigt. Dieser Datensatz wird verwendet, um eingehende Daten aufzunehmen, umzuwandeln und zu analysieren.
Vorteile des Data Lakehouse-Ansatzes
Der Data Lakehouse-Ansatz bietet viele Vorteile, wenn es darum geht, Datenanalyseprozesse zu vereinfachen und zu optimieren. Im Gegensatz zu einer einheitlichen Strategie, die oft zu Kompromissen führt, integriert die Lakehouse-Architektur einen Data Lake, ein Data Warehouse und spezialisierte Speicher, um eine einheitliche Governance und eine einfache Datenbewegung zu ermöglichen. Mit Amazon MWAA können Daten im Data Lake auf einfache, skalierbare und kosteneffiziente Weise transformiert und verschoben werden.
Komplexe Workflows erstellen
Ein weiterer Vorteil des Lakehouse-Ansatzes ist die Möglichkeit, komplexe Workflows zu erstellen. In der modernen Big-Data-Welt sind oftmals aufwendige Datenpipelines erforderlich, die viele interne und externe Dienste miteinander verbinden. Mit Managed Workflows können diese Abläufe nach einem Zeitplan oder bei Bedarf automatisch ausgeführt werden. Diese Workflows lassen sich über eine Web-Benutzeroberfläche oder eine zentrale Überwachungssoftware steuern.
ETL-Jobs managen
Eine Möglichkeit, mehrere ETL-Jobs (Extract – Transform – Load) zu koordinieren, ist die Verwendung von Managed Workflows. Sie können als Open-Source-Alternative verwendet werden, um mehrere Aufträge in einem beliebig komplexen ETL-Workflow zu orchestrieren, bei denen verschiedene Technologien eingesetzt werden. Beispielsweise kann man mithilfe von Managed Workflows mehrere AWS Glue-, AWS Batch– und Amazon EMR-Aufträge koordinieren, um die Daten zu kombinieren und für die Analyse vorzubereiten, wenn man bspw. die Korrelationen zwischen dem Engagement von Online-Benutzern und den prognostizierten Umsatzerlösen und Verkaufschancen untersuchen möchte.
Datenvorbereitung für maschinelles Lernen
Managed Workflows sind auch sehr hilfreich, wenn Daten für maschinelles Lernen vorbereitet werden. Es ist notwendig die Quelldaten zu sammeln, zu verarbeiten und zu normalisieren, damit ML-Tools wie Amazon SageMaker auf diesen Daten trainieren können. Managed Workflows ermöglichen es die Schritte zur Automatisierung der ML-Pipeline einfacher zusammenzufügen.
Beispiel
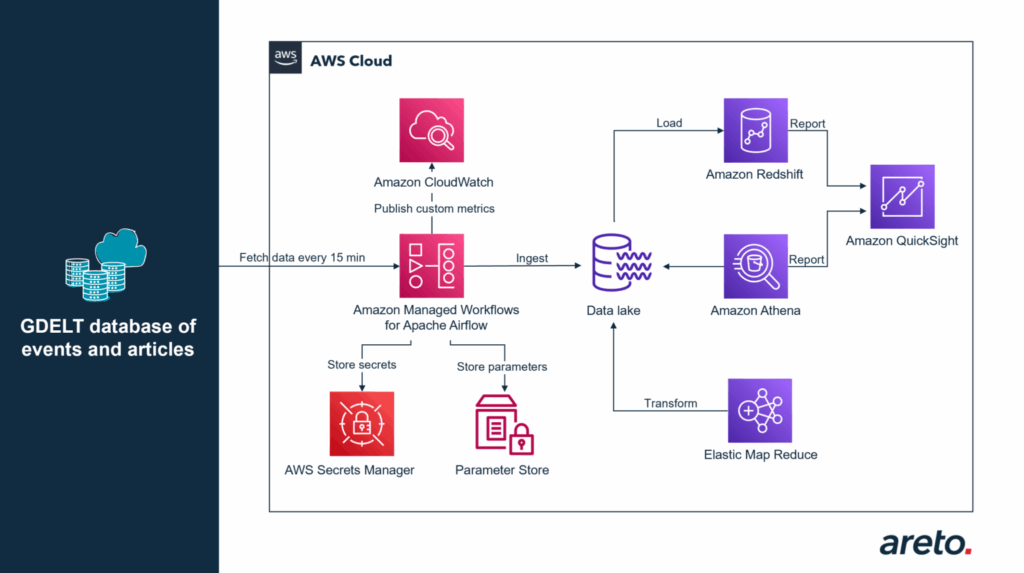
Das folgende Beispiel beschreibt die Analyse der GDELT-Ereignisdatenbank mit Amazon Athena und Amazon Redshift. GDELT nutzt hochentwickelte Tools, um Artikel aus der globalen Nachrichtenlandschaft in nahezu Echtzeit per Web-Scraping zu extrahieren und die berichteten Ereignisse und deren Orte zusammen mit einer Vielzahl von anderen Informationen zu kombinieren. Die Daten werden alle 15 Minuten über einen API-Endpunkt bereitgestellt und lassen sich in den Data Lake laden. AWS MWAA wird in diesem Beispiel verwendet, um einen Workflow zu erstellen, der die Dateien alle 15 Minuten herunterlädt und im CSV-Format in einem Amazon S3 Bucket speichert. Falls das Herunterladen der Dateien fehlschlägt, lässt sich die Workflow-Instanz jederzeit erneut für die fehlenden Dateien ausführen.
Der AWS-Dienst MWAA ermöglicht die Integration mit anderen AWS-Tools, wie zum Beispiel AWS Secrets Manager und AWS Systems Manager Parameter Store. Durch diese Integration können verschiedene Informationen wie API-Endpunkte, vertrauliche Daten, Amazon S3-Bucket-Namen und Umgebungsdetails gespeichert werden. Der DAG-Code (Directed Acyclic Graph) bleibt hierbei übersichtlich und lässt sich in mehreren Umgebungen und Projekten über verschiedene Teams hinweg wiederverwenden. Zusätzlich wird eine benutzerdefinierte Metrik mit der Anzahl der heruntergeladenen Ereignisse an Amazon CloudWatch gesendet, um die Entwicklung der Anzahl der Ereignisse im Laufe der Zeit zu analysieren.
Nachdem die Daten als CSV-Datei in S3 verfügbar sind, beginnt der Konvertierungsprozess in ein spaltenbasiertes Format, wie zum Beispiel Parquet. Dies verbessert die Leistung beim Lesen der Daten mittels Amazon Athena und Amazon Redshift Spectrum. Der nächste Schritt ist die Vorbereitung der Tabellen für Athena und das Laden in den Redshift Cluster. Diese Schritte können unabhängig voneinander durchgeführt werden. Mit Amazon Athena können Ad-hoc-Abfragen auf die verfügbaren Daten ausgeführt und Erkenntnisse in nahezu Echtzeit gewonnen werden. Mit Redshift hingegen, lassen sich komplexere Abfragen erstellen und es ermöglicht die Korrelation der Daten auf mehreren Dimensionen. Beispielsweise kann man herausfinden, ob interne Daten oder Tweets verfügbar sind, die zu den Artikeln passen, oder welchen Einfluss Nachrichten und Ereignisse auf die Aufrufe einer Website haben.
Ein praktisches Beispiel für die Verwendung von Amazon Athena zur Analyse der GDELT-Ereignisdatenbank ist im AWS Serverless DataLake Day Hands-on Lab verfügbar. Dieses Lab ist für die Selbststudium geeignet. Die Architektur ermöglicht eine skalierbare Datenanalyse, indem jede Komponente im Datenfluss in der Lage ist, mehr Ressourcen hinzuzufügen, wenn die Nachfrage steigt. Die Kosten der Architektur sind gut kalkulierbar, da sie sich an den tatsächlich genutzten Ressourcen orientieren.
Die Daten werden langlebig gespeichert durch die Nutzung von Amazon S3. Es besteht zudem die Möglichkeit, diese in einen sekundären Bucket in einer anderen Region für die Replikation zu speichern. Durch die Integration von Amazon MWAA mit vielen Diensten von AWS, kann die Umgebung sicher abgesichert werden, wie durch Identity Access Management (IAM) und Virtual Private Cloud (VPC).
Best Practices:
Folgende Ressourcen können Sie zum Aufbau und dem Verwenden von Amazon MWAA für effizientes Arbeiten nutzen:
- Verwenden Sie die offizielle Dokumentation von Apache Airflow Best Practices, um Aufgaben, Variablen und Unit-Tests für DAGs (Directed Acyclic Graphs) zu konfigurieren.
- Informieren Sie sich über die Security Best Practices von Amazon MWAA, um Daten im Ruhezustand und bei der Übertragung zu schützen, Berechtigungen zu verwalten und eine mandantenfähige Umgebung zu überwachen und zu überprüfen.
- Nutzen Sie den Troubleshooting Guide von Amazon MWAA, um häufige Probleme und Fehler zu erkennen und zu beheben.
- Verwenden Sie die Möglichkeit von Amazon MWAA lokal auszuführen, um Entwicklungszeit zu verkürzen und Testzeiten zu verringern.
- Referieren Sie auf die Airflow FAQ Seite, wenn Sie Fragen haben
- Informieren Sie sich über die neuen Funktionen in der Apache Airflow Version 2.0 und die Unterstützung von Amazon MWAA.
- Beachten Sie Upstream-Kompatibilität als Kernaspekt von Amazon MWAA und das open source release der Code-Änderungen von AWS in der Airflow Plattform.
Quelle: BIGDATA INSIDER von Constantin Gonzalez (Principal Solutions Architect bei AWS) und Ovidiu Hutuleac (Solutions Architect bei AWS)