


Die Datenintegration auf Unternehmensebene stellt hohe Anforderungen an Ihre Datenarchitektur und Designmethodik. Die Ergänzung einer Data Vault-Schicht ist dank der einzigartigen Fähigkeit von Data Vault zur langfristigen integrierten Speicherung von Daten eine hervorragende Entscheidung.
Der folgende Artikel befasst sich mit der Partnerschaft unter unseren Partnern Matillion und VaultSpeed. Es wird beschrieben, wie die Plattformen zusammenarbeiten, um eine Produktivitätssteigerungen mit Data Vault zu ermöglichen.
Matillion ist die Data Productivity Cloud – die Nr. 1 unter den Low-Code/No-Code-Plattformen (LC/NC) für die Entwicklung, Erstellung und Verwaltung von Cloud-Datenintegrationsprojekten. VaultSpeed auf der anderen Seite ist die führende Automatisierungsplattform für die Modellierung und das Design von Data Vault.
Voraussetzungen
Um Data Vault 2.0-Lösungen mit Matillion und VaultSpeed zu entwerfen und bereitzustellen, benötigen Sie:
- Zugang zu VaultSpeed
- Zugang zu Matillion ETL
- Eine gewisse Vertrautheit mit Data Vault 2.0 Konzepten ist von Vorteil
Was ist Data Vault?
Im Kern ist Data Vault eine Datenmodellierungstechnik. Sie wird am besten in der mittleren Schicht einer mehrschichtigen Datenarchitektur eingesetzt. Data Vault 2.0 geht darüber hinaus und umfasst ein ganzes Business-Intelligence-System, einschließlich einer agilen Entwicklungsmethodik.
Data Vault weist Ähnlichkeiten mit der Anker-Modellierung auf und hat mit dem RDF-Triplestore die natürliche Fähigkeit gemeinsam, mit geschäftlichen Änderungen im Laufe der Zeit umzugehen. Dies ist bekannt als Schema-Drift. Dank dieser Eigenschaften eignet sich Data Vault hervorragend für die Bewältigung der größten und anspruchsvollsten Datenintegrationsaufgaben. Er wird umso wertvoller, je mehr Datenquellen beteiligt sind.
Unten sehen Sie ein kleines Beispiel für ein Data Vault-Modell, das die Beziehung zwischen Einzelhandelskunden und Geschäften betrifft. In der Mitte modellieren die beiden “Hub”-Tabellen und ein “Link” das Transaktionsereignis des Besuchs eines Kunden in einem Geschäft. Sechs umliegende “Satellitentabellen” liefern alle kontextbezogenen Daten und befassen sich mit der Informationssicherheit.
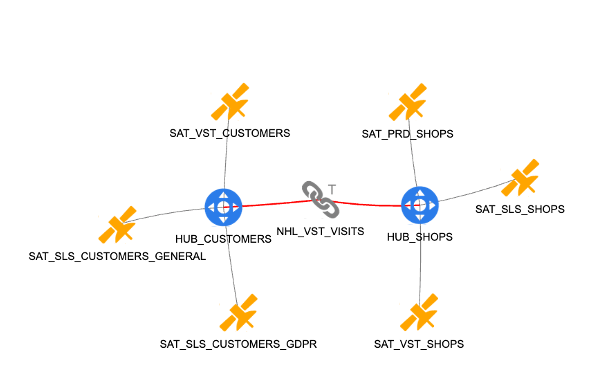
Im Vergleich zu 3rd Normal Form, einer weit verbreiteten Alternative, ist Data Vault wesentlich besser imstande, Schemadrifts zu bewältigen. Allerdings ist Data Vault komplexer zu gestalten und zu implementieren als 3rd Normal Form. Häufig wird eine nachgelagerte Datentransformation verwendet, um die Daten in einer besser konsumierbaren Form darzustellen – normalerweise als Sternschema. Daher eignet sich Data Vault gut für Produktivitätssteigerungen durch LC/NC und Automatisierung.
Konzeptuelle und Geschäftliche Modelle
Bei der Data Vault-Modellierung werden mehrere Quelldatenmodelle in ein einziges integriertes Data Vault-Modell überführt.
Ein Raw Data Vault wird verwendet, um die ungefilterten Daten aus der Quelle als Hubs, Links und Satellites zu speichern. Das Data Vault-Modell repräsentiert Ihr Unternehmen: Es sollte die Elemente, Attribute und Beziehungen enthalten, mit denen Ihre Mitarbeiter vertraut sind.
Der Aufbau eines konzeptionellen Datenmodells, das Ihr Unternehmen genau widerspiegelt, ist von großem Wert. Dieses konzeptionelle Modell enthält die Taxonomien und Ontologien, die verschiedene Konzepte in Ihrem Unternehmen beschreiben. Durch die gemeinsame Arbeit mit den Geschäftsanwendern an einem konzeptionellen Datenmodell werden einige der Unterschiede in der Bedeutung, den Definitionen und dem gemeinsamen Verständnis der Arbeitsweise des Unternehmens aufgedeckt.
Setzen Sie Ihr konzeptionelles Modell in die Praxis um, indem Sie es in das reale Data-Vault-Modell integrieren. Dieses wird zum Entwurfsplan für Ihre relationale Datenbank, einschließlich Spaltennamen, Längen, Primär- und Fremdschlüsseln.
Das konzeptionelle Modell stimmt nie genau mit den Quelldatenmodellen überein. Es gibt Unterschiede in den implementierten Taxonomieebenen. Mehrere Geschäftsschlüssel werden sich in einzelnen Quellstrukturen verheddern. Modellgesteuerte Automatisierung kann hier Abhilfe schaffen.
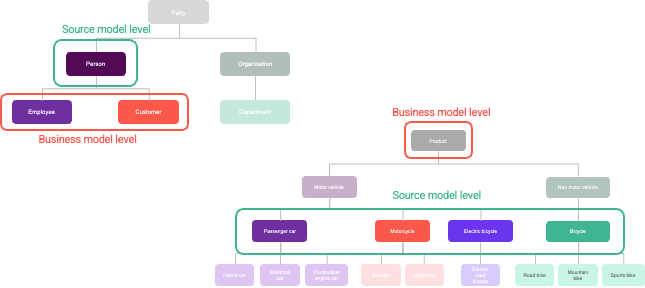
Unterschiede in den Taxonomie-Ebenen in Quell- und Zieldatenmodellen
Als natürlicher Bestandteil eines sich stetig weiterentwickelnden Unternehmens ändern sich konzeptionelle Modelle im Laufe der Zeit. Es gibt nie eine einzige, dauerhafte, ideale Darstellung, auf die sich alle einigen können. Die modellgesteuerte Automatisierung von VaultSpeed sorgt dafür, dass diese Änderungen effizient gehandhabt werden können.
Wie VaultSpeed die Modellierung von Data Vault verbessert
VaultSpeed konzentriert sich in erster Linie auf Data Vault 2.0 zur Automatisierung der Integration von Daten aus verschiedenen Quellen in ein Cloud Data Warehouse (CDW).
Die Automatisierung von Data Vault in VaultSpeed zielt darauf ab, Ihr Data Vault so zu modellieren, dass es den Geschäftsanforderungen entspricht. Der gesamte Prozess ist No-Code. Die Schnittstelle ist ein parametrisierter Datenmodellierer mit Objekttyp- und Attributtyp-Tagging. Hier wird das gesamte Data Vault-Modell entworfen. Anschließend generiert das Tool die DDL sowie die Transformations- und Orchestrierungslogik für die Implementierung in Matillion.
Lassen Sie uns dies anhand eines Beispiels erläutern. Stellen Sie sich ein Autohaus vor, das den Überblick über seine Kunden behalten möchte, die seine verschiedenen Filialen besuchen. Es gibt drei Datenquellen, die integriert werden müssen:
- Das CRM-System
- Das Lagerverwaltungssystem
- Ein Datenstrom zur Verfolgung von Werkstattbesuchen
VaultSpeed hat einen siebenstufigen Ansatz zur Automatisierung dieses Prozesses.
Schritt 1 – Sammeln von Metadaten
VaultSpeed sammelt Metadaten aus jeder der drei Quellen, um den Modellierungsprozess zu beschleunigen. Es arbeitet mit JDBC, so dass Tausende von Quellentypen zugänglich sind.
Schritt 2 – Tech-Stack-Parametrisierung
Auf diese Weise wird die Komplexität des Datenstapels gehandhabt. Der Anwender wählt die Technologien und Versionen seiner Quellen sowie die Zielplattform aus. Darüber hinaus gibt es eine Auswahl an Einstellungen für Data Vault 2.0, einschließlich der verwendeten Matillion Change Data Capture (CDC) Methode. Die Einstellungen in Bezug auf CDC sind in der nachstehenden Abbildung dargestellt.

CDC-Parametereinstellungen in VaultSpeed zur nahtlosen Integration mit der CDC-Lösung von Matillion
Schritt 3 – Abbildung des Geschäftsmodells
Das Data Vault-Modell muss Ihre spezifische Organisation und Ihre Prozesse widerspiegeln. VaultSpeed macht die geschäftsmodellbasierte Automatisierung einfach. Zunächst kann der Bediener ein bestehendes konzeptionelles Datenmodell mithilfe von REST-API-Integrationen einfach importieren. Anschließend wird mit einem leistungsstarken Quelltext-Editor das Data Vault-Modell erstellt.
In diesem Stadium kann der Anwender geschäftliche Schlüssel markieren, Beziehungen ändern oder hinzufügen, Hubs gruppieren oder Quellentitäten und/oder Satelliten aufteilen. Die aus den Quellen gewonnenen Metadaten geben den Benutzern einen Vorsprung im Modellierungsprozess.
Das resultierende Datenmodell ist Data Vault 2.0-konform und wird von VaultSpeed in Strukturen übersetzt.
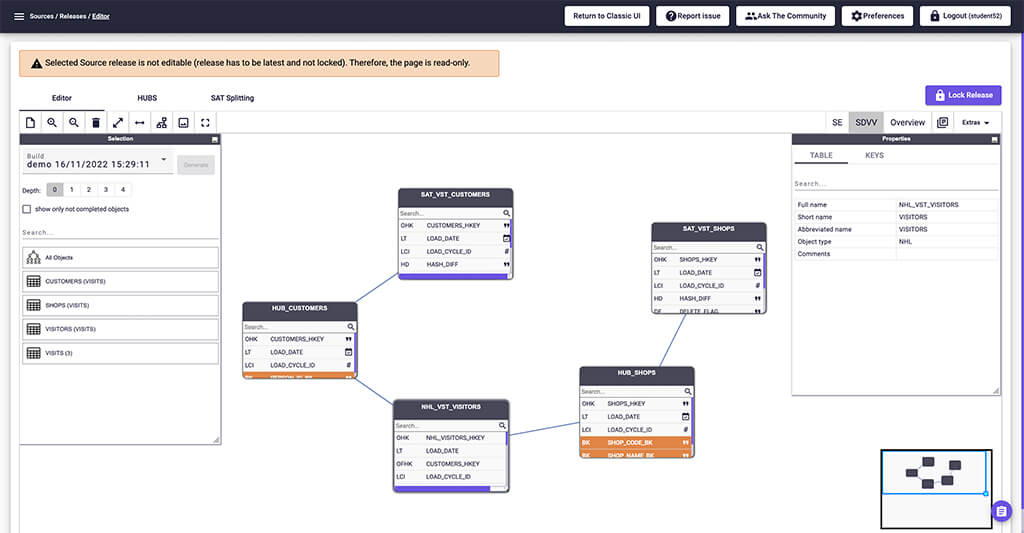
Das vorgeschlagene DV2-Modell auf der Grundlage Ihres Geschäftsmodells
Schritt 4 – ETL & DDL-Code-Generierung
VaultSpeed generiert den DDL-Code zur physischen Erstellung des Datenmodells. Dieser wird auf dem Ziel-CDW – zum Beispiel Snowflake oder Databricks – bereitgestellt. Dies kann entweder über den sicheren Agenten von VaultSpeed oder über ein DataOps-Tool erfolgen.
VaultSpeed generiert auch ETL-Mapping-Anweisungen für die Datentransformation in Form von Matillion ETL-Transformationsjobs.
Mit einem Knopfdruck wird der Codegenerierungsprozess gestartet.
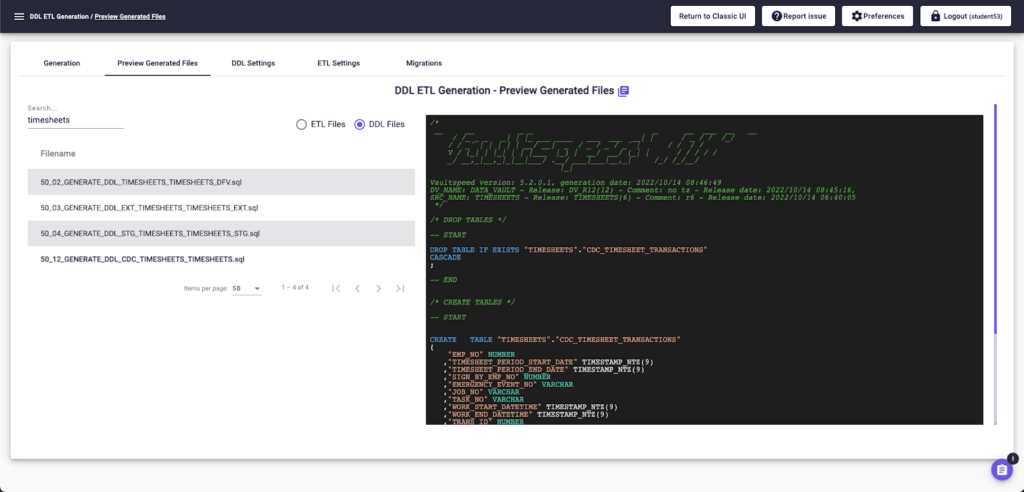
Beispiel eines von VaultSpeed generierten DDL-Codes
Schritt 5 – Pipeline-Bereitstellung
VaultSpeed stellt eine Verbindung zu Matillion und dem zugrunde liegenden CDW her und sendet Anweisungen zur Erstellung der ETL-Mappings und des Data Vault-Modells. Ein Sicherheitsagent stellt die generierten Aufträge automatisch in Matillion bereit.
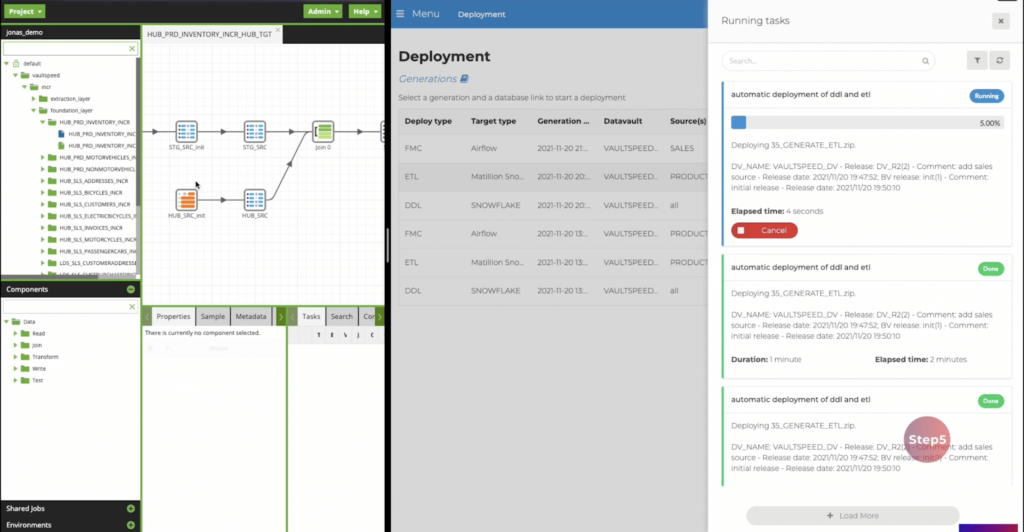
Bereitstellung von ETL-Mappings in Matillion ETL
Schritt 6 – Orchestriertes Laden von Daten
Sobald die Pipeline bereitgestellt ist, ist das System bereit, Daten in das Data Warehouse zu laden und sie so umzuwandeln, dass analysierbare Daten entstehen. Nachdem VaultSpeed das Design und das Modell bereitgestellt hat, übernimmt Matillion an dieser Stelle und stellt die Laufzeit zur Verfügung.
Schritt 7 – Wiederholung
Wann immer sich Quellen oder Anforderungen ändern, wiederholen Sie die Schritte 1-6, um Ihr Data Vault 100%ig relevant und auf Kurs zu halten.

Die 6 Schritte des Data Vault Modellierungsprozesses
Wie Matillion Ihre Produktivität steigert
Data Vault-Modelle werden in der mittleren Schicht einer Datenarchitektur verwendet. Matillion wird für den Entwurf und die Implementierung der umgebenden Schichten verwendet:
- Vor dem Laden der Daten
- Nach der Transformation der Daten, zum Beispiel in ein Sternschema
Matillion fungiert als Orchestrator, der die in VaultSpeed entworfenen Jobs ausführt. Matillion stellt auch sicher, dass das Laden der Daten, die Aufgaben des Datentresors und die Datentransformationen in der richtigen Reihenfolge erfolgen.
Die End-to-End-Datenarchitektur sieht wie folgt aus:
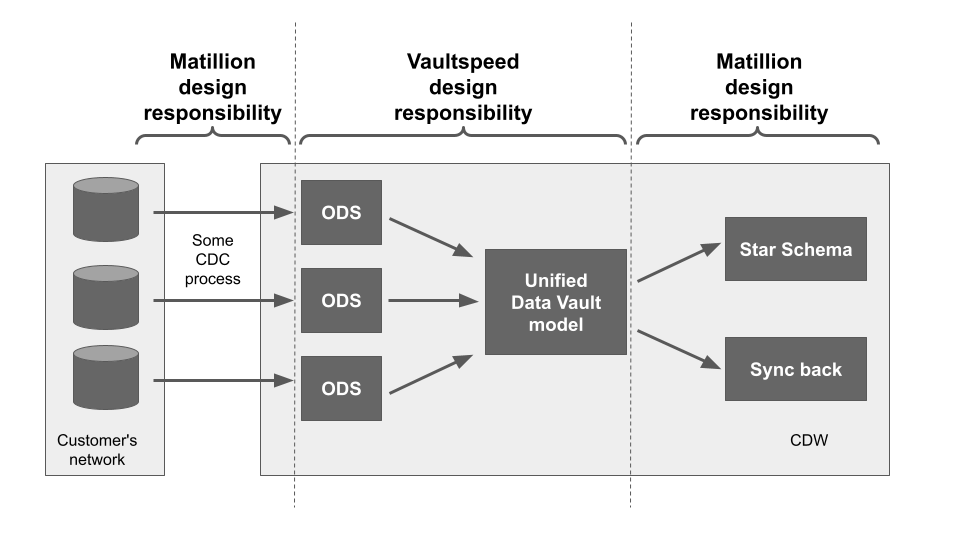
Die Low-Code / No-Code Datenintegrationsschnittstelle von Matillion beschleunigt die Entwicklung und Bereitstellung von Data Vault, Star Schema und 3rd Normal Form Datenmodellen.
Sie können wählen, ob Sie die Änderungsdatenerfassung von Matillion Data Loader im Batch- oder CDC-Modus verwenden möchten.
Das Prozessmodell, das zeigt, wie Matillion und VaultSpeed zusammenarbeiten, sieht wie folgt aus:
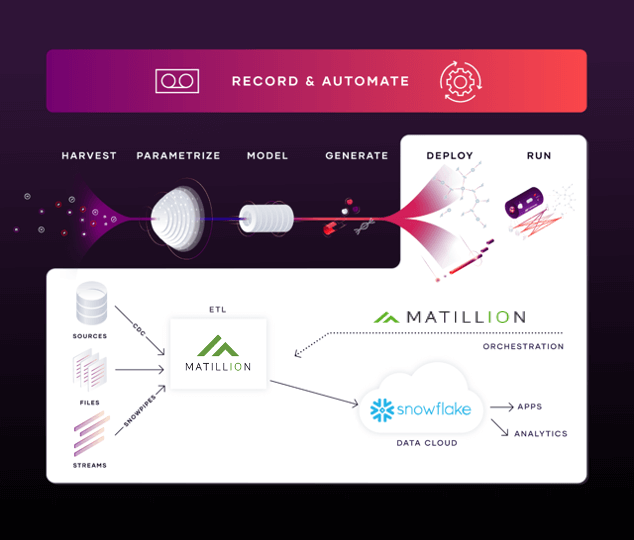
VaultSpeed- und Matillion-Integration für Snowflake
Unsere Berater*innen helfen Ihnen gerne, Matillion und DataVault zu integrieren!